


iPhone 12 Pro is the beginning of the end for photos and video as we know them.
1,000 sensors in your pocket
Apple just announced iPhone 12 Pro which includes LiDAR. In short, it scans the surrounding space using what Apple describes as “invisible light beams” that your phone uses to create a virtual 3D mapping of the space.
Three years ago, they announced iPhone X with the TrueDepth camera, projected infrared dots that your phone uses to create a virtual 3D mapping of your face.
At the time, I wrote a piece called Replace Your Face: iPhone X as the First Mass Market AR Device, about how that technology could be combined with deepfakes to create surprising outcomes.

Here are visualizations of iPhone’s LiDAR and TrueDepth camera.


As you can see, these are variations on the same theme: using light to allow the iPhone’s software to construct a virtual model of the world that matches the real thing. Mostly you will hear about how these sorts of tools enable augmented reality objects to seamlessly blend in with real reality.
But I believe there is something else developing here that is equally as exciting– an emerging trend that I expect will play out in the coming years.
Instructions, not images
What first got me thinking about it was NVIDIA Maxine, announced last week.
In particular, this caught my eye:
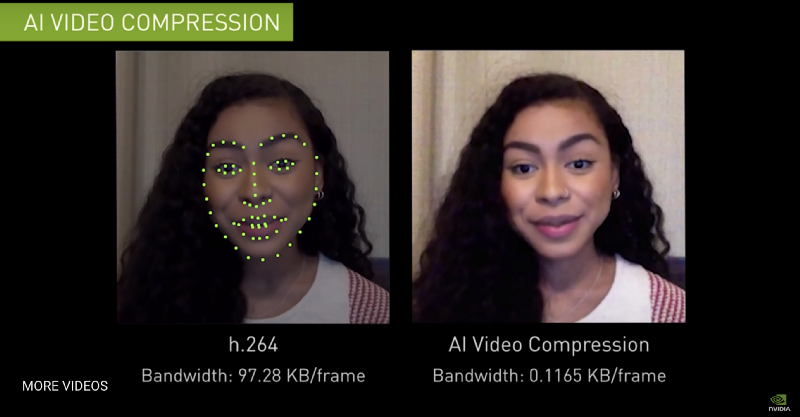
Calling it AI video compression, they are constructing a virtual model of the speaker’s face from the original video on the left, and then they recreate a representation of her face on the right. It is similar to the way Memojis work, except it is using her own face.
Imagine you are video conferencing with this woman, and you think you are seeing a livestream video of her face, but instead you are seeing a realtime rendered deepfake, of her own face, happening client-side on your device. (What do we call it since it’s her own face? A deepreal?)
Rather than sharing a video file, they are sending instructions (text) about how to construct her face. The difference between the two approaches is a 99.99% reduction in size! That means much faster transmission and much lower latency.
It also means that the rendering on the receiving end could actually yield a better quality video than the input, as NVIDIA also demonstrates in the above video. Even weirder, you could just use the same movement data but display a completely different face. This is exactly the kind of stuff I was writing about in Replace Your Face, but now we’re seeing it coming to fruition.
A new type of photography
So with that all in mind, the iPhone 12 Pro LiDAR announcement got my brain spinning in an even crazier way: what if eventually all photos and videos are taken and rendered like the NVIDIA AI video compression?
In other words, you wouldn’t actually take photos or videos at all. Instead you would just capture the mapping data in order to reconstruct the scene later. Apple has talked a lot about computational photography in the past few years, but what if we took it to the extreme? Here’s how it might work:
- First, there would be a “scan” of your surroundings, using camera(s) to capture colors, textures, details, etc. + using the LiDAR and other sensors to create a virtual mapping of the scene, separating out the background, objects, people, and so on.
- Once the virtual model is in place, all subsequent photos/video that the user takes would actually just be captures of the differences in the mapping data.
- When viewing the images or videos later, the original details would be “deepfaked” back on top, giving the appearance of real photos and videos, but in reality they would be composites of the initial scanning data + the new mapping data.
No pixels are harmed
Each new photo would have that same .1 KB file size, because it would just be text instructions, not pixels.
These would not be photographs in the traditional sense, but instead realtime rendered virtual environments, almost like a video game of your real life.
Why would we want this? First off, again, media could be uploaded and downloaded much faster, improving latency dramatically, which is vital for AR/VR.
But the really wild part is that it would also allow you to manipulate the images or video post facto in a brand new way. What you would have is the equivalent of a Pixar movie set: the background, the objects, the people– all as separate elements that you could move or swap out or edit the appearances of. And you would be able to change the lightning and camera angles after the fact as well.
Imagine an evolution of the new Apple ProRAW format that contained all of that original sensor and mapping data, not only for stills but for video too.
The beginning
What we are seeing are just breadcrumbs of a possible future, but I believe these concepts will unfold more over time. What we think of as photo/video today will be replaced by 3D spacial data. Eventually the concept of photography, of capturing the light of a single instance, to be viewed only as it was in that exact moment, will become quite quaint. Like most technology trends, it won’t be a 0 to 1 change. We’re already well down this road whether we realize it or not.



